RStudio recently released the sparklyr package that allows users to connect to Apache Spark instances from R. In addition, this package offers dplyr integration, allowing you to utilize Spark as you use dplyr functions like filter and select, which is very convenient. The package will also assist you in downloading and installing Apache Spark if it is a fresh install. This post covers the local install of Apache Spark via sparklyr and RStudio in Windows 10.
As per the guide, install the latest preview release of RStudio and run the following commands to install sparklyr
install.packages("devtools")
devtools::install_github("rstudio/sparklyr")
Once installed, you should see a new tab beside Environment and History tabs in RStudio – the Spark tab. You will be able to see a “New Connection” button.
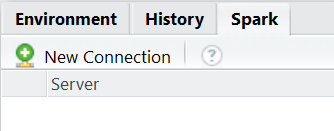
On clicking the button, you will be able to set various options from Spark and Hadoop versions (at time of writing – Spark 1.6.2 and Hadoop 2.6) to connecting to local or remote Spark clusters and whether to use dplyr as the DB interface. Let’s use the defaults here.
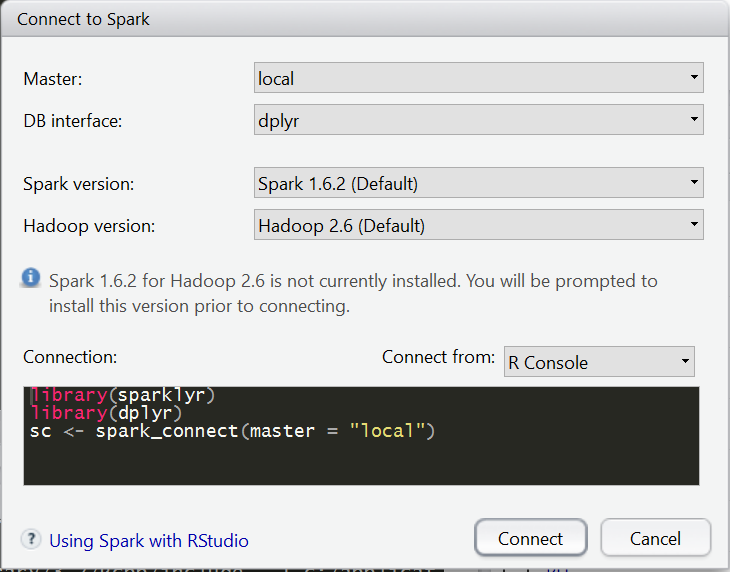
If this is a fresh install, RStudio will prompt a confirmation dialog box:

Upon clicking “Install”, RStudio will then proceed to download and install Apache Spark for you and attempt to connect to the local Spark instance.
At this stage you might receive a similar error message below:
Error in start_shell(scon, list(), jars, packages) :
Failed to launch Spark shell. Ports file does not exist.
Path: C:\Users\<USERNAME>\AppData\Local\rstudio\spark\Cache\spark-1.6.2-bin-hadoop2.6\bin\spark-submit.cmd
Parameters: --packages "com.databricks:spark-csv_2.11:1.3.0,com.amazonaws:aws-java-sdk-pom:1.10.34" --jars "<PATH TO R PACKAGES>\R\win-library\3.2\sparklyr\java\rspark_utils.jar" sparkr-shell D:\Temp\RtmpO0cLos\file23c0703c73bf.out
In addition: Warning message:
running command '"C:\Users\<USERNAME>\AppData\Local\rstudio\spark\Cache\spark-1.6.2-bin-hadoop2.6\bin\spark-submit.cmd" --packages "com.databricks:spark-csv_2.11:1.3.0,com.amazonaws:aws-java-sdk-pom:1.10.34" --jars "<PATH TO R PACKAGES>\R\win-library\3.2\sparklyr\java\rspark_utils.jar" sparkr-shell <PATH TO TEMP DIRECTORY>\Temp\RtmpO0cLos\file23c0703c73bf.out' had status 127
If you meet this error, it may be due to Windows security permissions of the .CMD files for Apache Spark. To resolve this issue, go to the Apache Spark install directory, which should be C:\Users\<USERNAME>\AppData\Local\rstudio\spark\Cache\spark-1.6.2-bin-hadoop2.6\bin\. You should be able to see the files ending with extension .cmd. At the time of writing, the files include
beeline.cmd
load-spark-env.cmd
pyspark.cmd
pyspark2.cmd
run-example.cmd
run-example2.cmd
spark-class.cmd
spark-class2.cmd
spark-shell.cmd
spark-shell2.cmd
spark-submit.cmd
spark-submit2.cmd
sparkR.cmd
sparkR2.cmd
For each of the these .CMD files, edit the security permission for your USERNAME to allow “Read & execute” as shown below:

After editing the permissions, when you attempt to connect to Spark by running the commands below, you should not experience any more errors.
> library(sparklyr)
> library(dplyr)
> sc <- spark_connect(master = "local")
To verify, you can try out the examples from the RStudio guide, or try the adapted example below:
> iris_tbl <- copy_to(sc, iris)
> iris_tbl
Source: query [?? x 5]
Database: spark connection master=local app=sparklyr local=TRUE
Sepal_Length Sepal_Width Petal_Length Petal_Width Species
<dbl> <dbl> <dbl> <dbl> <chr>
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
7 4.6 3.4 1.4 0.3 setosa
8 5.0 3.4 1.5 0.2 setosa
9 4.4 2.9 1.4 0.2 setosa
10 4.9 3.1 1.5 0.1 setosa
# ... with more rows
>
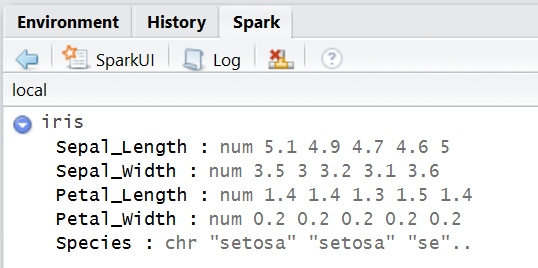
Visually, you would be able to see the data frame in the Spark tab as well:
You can now have fun with Apache Spark in RStudio! You might also want to add the Apache Spark install directory C:\Users\<USERNAME>\AppData\Local\rstudio\spark\Cache\spark-1.6.2-bin-hadoop2.6\bin to your path so that you can run Spark shells (sparkr,pyspark and spark-shell) in the command line. For example, with PySpark, you should see a similar welcome screen as below after the initialization messages.